1.3 KiB
Report
Experiment 1
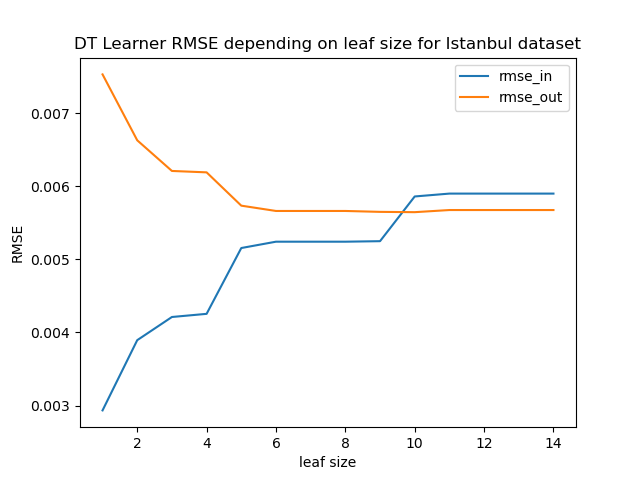
Significant overfitting occurs for leaf sizes smaller than five. The chart shows
that the root-mean-square-error is significantly higher for the test data
(rmse_out) for leaf sizes smaller than five.
Between five and nine, the error for the test data is only slightly higher, so there is small overfitting. Beyond that, the errors increase, and the error for the test data is lower than for the training data. In other words, there is no more overfitting for leaf sizes greater than nine.
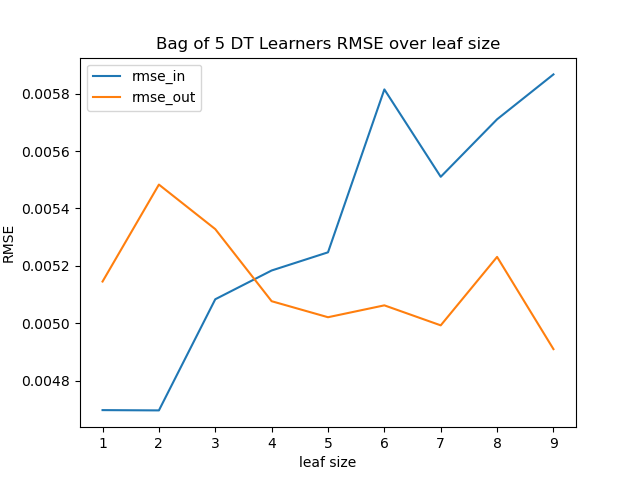
Experiment 2
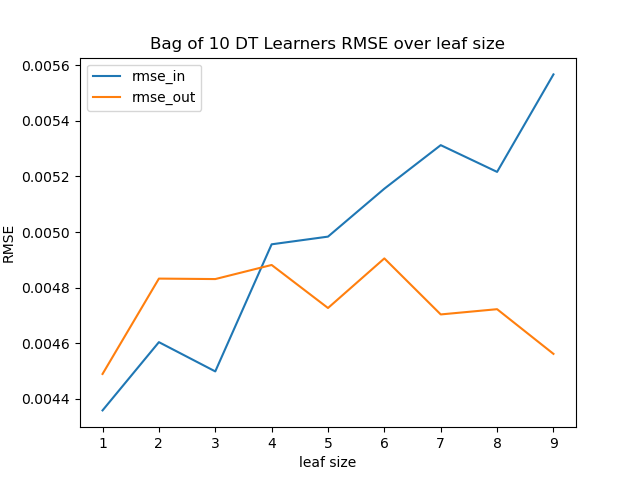
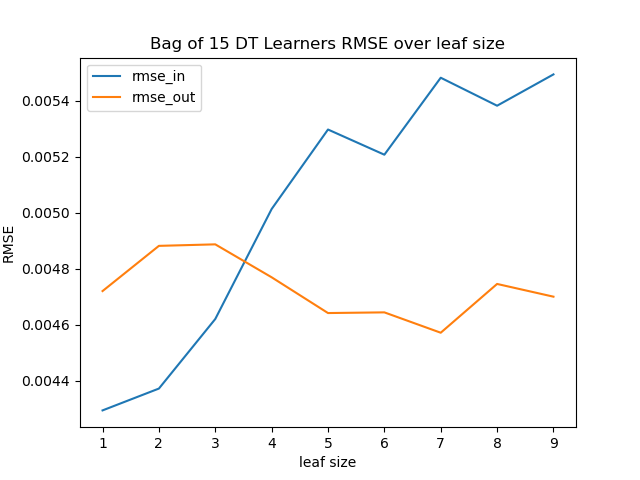
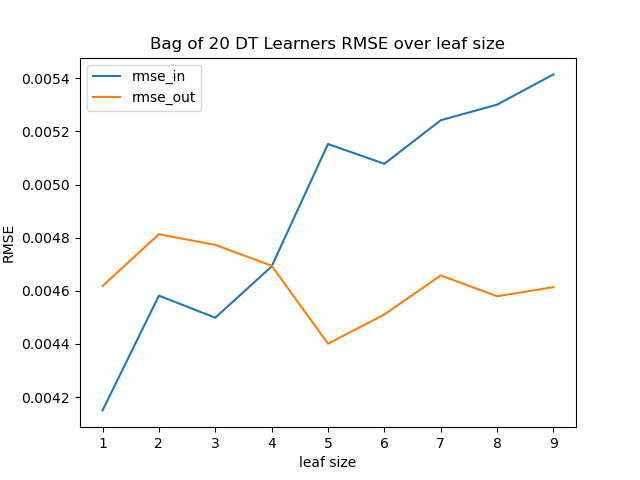
For all bag sizes, the difference of the RMSE for the training data and the test data is smaller than without bagging. The test data still has a lower RMSE up to a leaf size of five. For greater leaf sizes, the RMSE for the test data is smaller than for the training data for all bag sizes, so there is no overfitting.
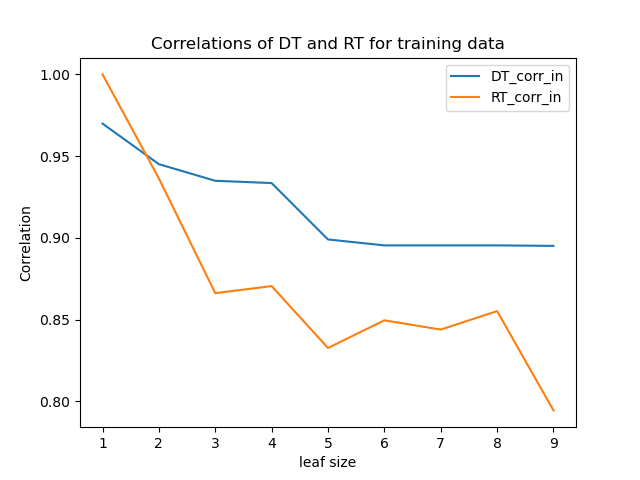
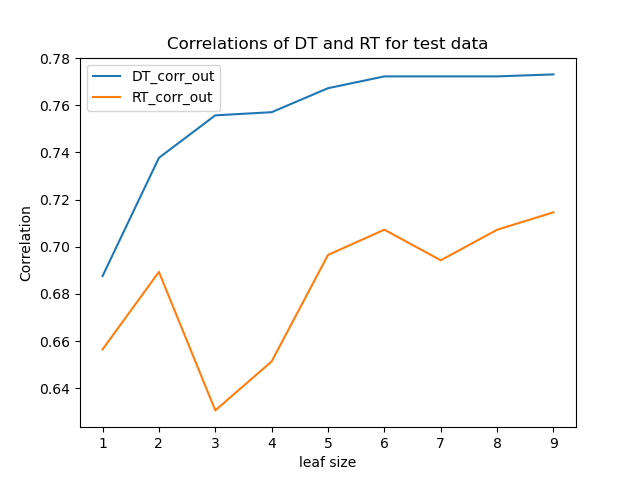
Experiment 3
The Random Tree learner has a correlation of one for the training data. In other words, it fits the training data perfectly. Consequently, the correlation for the test data is worse than for the Decision Tree learner. The DT learner has a higher correlation than the RT for all other leaf sizes, both for the training and the test data.